Streaming data from DynamoDB to Aurora

Intro
Amazon DynamoDB operates at web scale and can ingest streams of high-velocity data at a rate of millions/second. Now imagine needing to replicate this stream of data into a relational database management system (RDBMS), such as Amazon Aurora. Suppose that you want to slice and dice this data or otherwise perform mapping functions related to business logic unto them prior to persistence.
To effectively replicate data from DynamoDB to Aurora, a reliable, scalable data replication (ETL) process needs to be built. In this post, I will show you how to build such a process using a serverless architecture with Amazon DynamoDB Streams and .NET on AWS Lambda.
Definitions
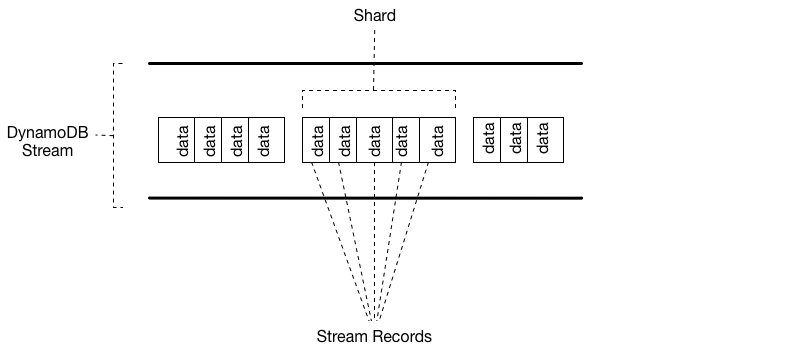
Amazon DynamoDB Streams
DynamoDB Streams captures a time-ordered sequence of item-level modifications in any DynamoDB table and stores this information in a log for up to 24 hours. Applications can access this log and view the data items as they appeared before and after they were modified, in near-real time. Encryption at rest encrypts the data in DynamoDB streams.
A DynamoDB stream is an ordered flow of information about changes to items in a DynamoDB table. When you enable a stream on a table, DynamoDB captures information about every modification to data items in the table.
Whenever an application creates, updates, or deletes items in the table, DynamoDB Streams writes a stream record with the primary key attributes of the items that were modified. A stream record contains information about a data modification to a single item in a DynamoDB table. You can configure the stream so that the stream records capture additional information, such as the "before" and "after" images of modified items.
DynamoDB Streams helps ensure the following:
- Each stream record appears exactly once in the stream.
- For each item that is modified in a DynamoDB table, the stream records appear in the same sequence as the actual modifications to the item.
DynamoDB Streams writes stream records in near-real time so that you can build applications that consume these streams and take action based on the contents.
Amazon Aurora
Amazon Aurora is a MySQL and PostgreSQL-compatible relational database built for the cloud that combines the performance and availability of traditional enterprise databases with the simplicity and cost-effectiveness of open-source databases.
Aurora is up to five times faster than standard MySQL databases and three times faster than standard PostgreSQL databases. It provides the security, availability, and reliability of commercial databases at 1/10th the cost.
Amazon Aurora is fully managed by Amazon Relational Database Service (RDS), which automates time-consuming administration tasks like hardware provisioning, database setup, patching, and backups.
Design Considerations
Alternatives
There's a landmark article on the AWS Database blog from 2017 that details a design for streaming data from DynamoDB to Aurora using AWS Lambda and Amazon Kinesis Firehose.
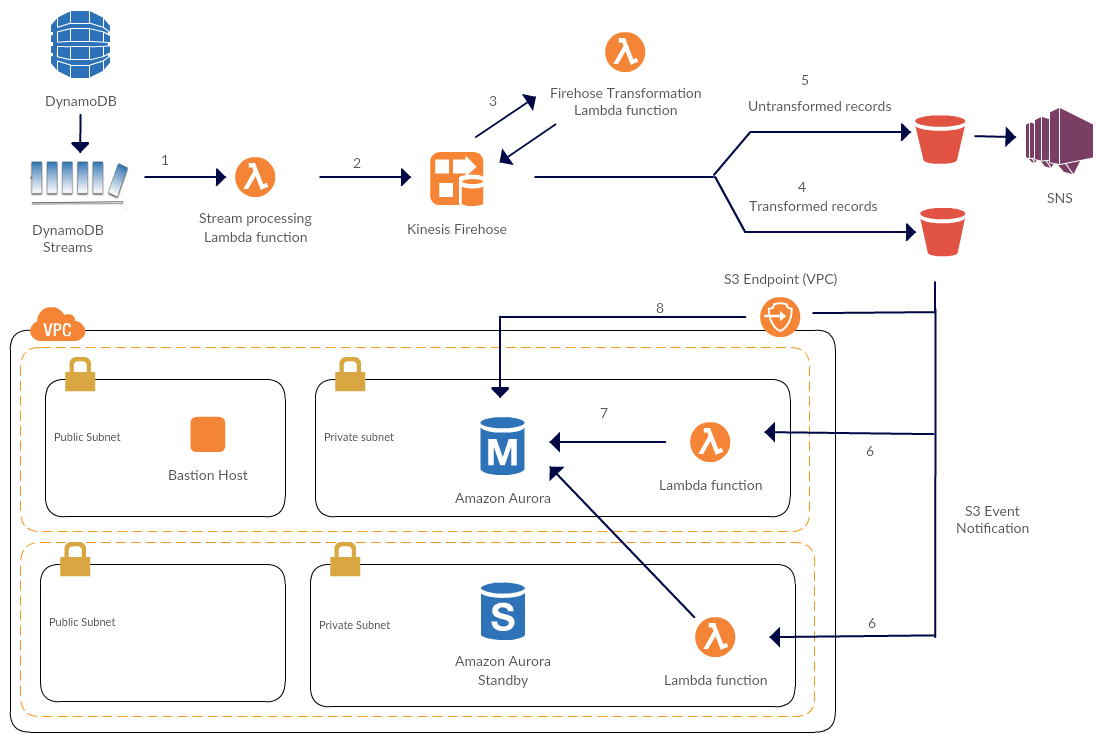
It's a great reference design but it might potentially end up costing your business quite a bit of money in cloud billing due to Kinesis Firehose pricing which is...discouraging, especially so for SaaS startups working on a budget.
The base function of a Kinesis Data Firehose delivery stream is ingestion and delivery. Ingestion pricing is tiered and billed per GB ingested in 5KB increments (a 3KB record is billed as 5KB, a 12KB record is billed as 15KB, etc.). That means that you're looking at > $200/day for every DynamoDB table with transaction numbers roughly equal to a million per day.
That may not sound terrible but it's probably (definitely?) more expensive that that same DynamoDB table bill itself and that's just wrong...or perhaps I've always worked in environments where I had to be wary of cloud bills 🤷♂️
Proposal
The system proposed above, served as the starting point for my idea of streaming data from DynamoDB to Aurora without using Kinesis Firehose but by grouping every 100 events in a given stream (which is the current system max value) before invoking an AWS Lambda function which will utilize an Object-Relational Mapper (Entity Framework in this case) to commit all those items to Aurora in a single database transaction.
Trade-offs
There's one potentially important trade-off of this design versus the Kinesis Firehose one, which is relevant to the density of your DynamoDB table's events stream. Using a Kinesis Firehose delivery stream, your data are streamed all the way through from DynamoDB to Aurora regardless of volume or frequency whereas a system like the one I am proposing streams data from DynamoDB to Lambda but then batches those which means that if your events stream volume is really low or very infrequent, it might take a few seconds before those are committed to Aurora.
This applies to all the other typical constraints of dealing with a SQL database: connection limits, timeouts etc. If your application processes data fast enough that N Lambdas concurrently persist DynamoDB events to Aurora, that's N database connections right there.
.NET Implementation
Building this library on top of the generic event handler function that I talked about in a previous post, we need a contract, one that a Lambda function's entry point should be able to call:
public interface
IStreamEventHandler<TDynamoDBEvent> where TDynamoDBEvent : class
{
Task HandleAsync(TDynamoDBEvent dynamodbEvent,
ILambdaContext context);
}There's something going on here beyond the provided method, notice the interface's generic constraint: TDynamoDBEvent needs to be a class; specificaly the DynamoDBEvent class from the Amazon.Lambda.DynamoDBEvents NuGet package.
Next, we'll need to add a reference to our existing generic EventHandler library from the previous post in order to implement the EventBridgeEventHandler class that inherits from the IEventHandler<T> interface defined there, where <T> is the ScheduledEvent.
public class DynamoDBEventHandler<TDynamoDBEvent>
: IEventHandler<DynamoDBEvent> where TDynamoDBEvent : class
{
private readonly ILogger _logger;
private readonly IServiceProvider _serviceProvider;
public DynamoDBEventHandler(ILoggerFactory loggerFactory,
IServiceProvider serviceProvider)
{
_logger = loggerFactory?.CreateLogger("DynamoDBEventHandler")
?? throw new ArgumentNullException(nameof(loggerFactory));
_serviceProvider = serviceProvider
?? throw new ArgumentNullException(nameof(serviceProvider));
}
public async Task HandleAsync(DynamoDBEvent input,
ILambdaContext context)
{
using (_serviceProvider.CreateScope())
{
var handler = _serviceProvider
.GetService<IStreamEventHandler<TDynamoDBEvent>>();
if (handler == null)
{
_logger.LogCritical(
$"No INotificationHandler<{typeof(TDynamoDBEvent).Name}> could be found.");
throw new InvalidOperationException(
$"No INotificationHandler<{typeof(TDynamoDBEvent).Name}> could be found.");
}
await handler.HandleAsync(input, context);
}
}
}Pretty straightforward, we just wire up the logging factory & dependency injection services here, add some rudimentary exception handling and asynchronously process this batch of DynamoDB events.
That's all it is! Before we move on to using our new library in a Lambda function .NET project though, it's worth discussing the DI part briefly.
Microsoft has provided its own implementation of a dependency injection container in .NET (in the form of a NuGet package) since .NET Core 2.1, called Microsoft.Extensions.DependencyInjection.
If you're looking to do DI as part of any library, you'll need to implement the IServiceCollection interface in a static class, so that the framework is able to collect the necessary service descriptors.
For our library, this will look like this 👇🏻
public static class ServiceCollectionExtensions
{
public static IServiceCollection
UseStreamEventHandler<TDynamoDBEvent, THandler>
(this IServiceCollection services)
where TDynamoDBEvent : class
where THandler : class, IStreamEventHandler<
TDynamoDBEvent>
{
services.AddTransient<
IEventHandler<DynamoDBEvent>, DynamoDBEventHandler<
TDynamoDBEvent>>();
services.AddTransient<
IScheduledEventHandler<TDynamoDBEvent>,
THandler>();
return services;
}
}Using the Library with an AWS Lambda .NET project template
Let's create an AWS .NET Lambda project: dotnet new lambda.EmptyFunction. If you've missed the part about installing the AWS project templates for the dotnet CLI, please check this previous post.
Next, reference both the generic Event function library as well as the DynamoDB specific one you just created.
Modify Function.cs, which is the entry point for Lambda function invocations as follows:
public class Function : EventFunction<ScheduledEvent>
{
protected override void Configure(
IConfigurationBuilder builder)
{
builder.Build();
}
protected override void ConfigureLogging(
ILoggerFactory loggerFactory,
IExecutionEnvironment executionEnvironment)
{
loggerFactory.AddLambdaLogger(new LambdaLoggerOptions
{
IncludeCategory = true,
IncludeLogLevel = true,
IncludeNewline = true
});
}
protected override void ConfigureServices(
IServiceCollection services)
{
// TODO: services registration (DI) &
// environment configuration/secrets
services.UseNotificationHandler<
ScheduledEvent,
YourAwesomeImplDynamoDBEventHandler>();
}
}Startup.csY'all know exactly what's up above already. All that's left at this point is to create a class to implement your business logic, YourAwesomeImplDynamoDBEventHandler.cs.
public class YourAwesomeImplDynamoDBEventHandler : IStreamEventHandler<
DynamoDBEvent>
{
private readonly ILogger<
YourAwesomeImplDynamoDBEventHandler> _logger;
private readonly IMapper _mapper;
private readonly AuroraContext _db;
public YourAwesomeImplDynamoDBEventHandler(
ILogger<YourAwesomeImplDynamoDBEventHandler> logger,
IMapper mapper, AuroraContext db)
{
logger = _logger ??
throw new ArgumentNullException(nameof(logger));
_mapper = mapper;
_db = db;
}
public async Task HandleAsync(
DynamoDBEvent dynamodbEvent,
ILambdaContext context)
{
using (_db)
foreach (var record in input.Records)
{
await _db.YourDBModelClass.AddAsync(record);
}
await _db.SaveChangesAsync();
}
}If your model's member types differ between the DynamoDB and Aurora tables or you need to operate on those members' values for reasons related to your business logic, you could use a concrete implementation of the IMapper interface, like AutoMapper or similar, to do some object-to-object mapping prior to using Entity Framework for data persistence.
Lastly, deploy the Lambda function using the Amazon.Lambda.Tools CLI by running `dotnet lambda deploy-function Sch.
If you've missed the part about the installation & usage of this .NET global tool, please check the end of the ".NET Implementation" section on this previous post.
What's next
This post concludes my 8-part foray into designing elastic and cost-effective event-driven, serverless software systems in AWS.
I plan on writing about serverless observability next; it's a topic near and dear to my engineer's heart which will serve as the logical connection between my 2021 blogging (which was 100% focused on serverless) and my blogging for 2022 which will be focused into production systems reliability.
References