Event-Driven Architectures: Motivation

This new blog series is a result of both my desire to write about this subject as well as a response to the numerous requests I received over the past couple of months on Twitter to facilitate such a dialogue between fellow serverless aficionados and technical leads who are contemplating moving some part of their enterprise (or startup) workloads from a server-hosted, in-process architecture to an event-driven architecture on a serverless platform.
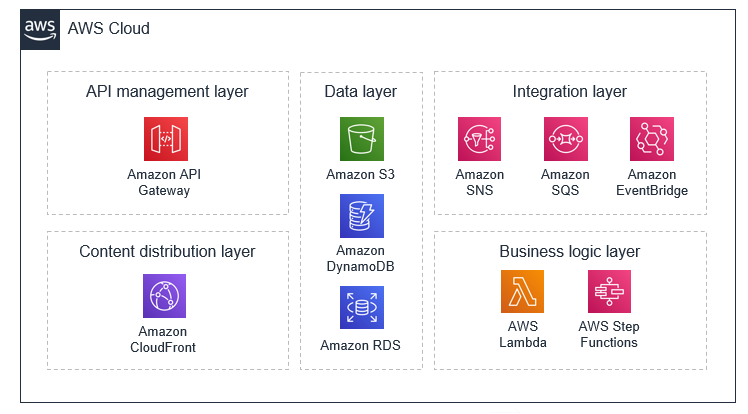
Over the course of this blog series, I plan on showing how common software use cases, specifically web-based SaaS ones, can be designed in a serverless computing platform; the benefits and trade-offs there of.
While I would've loved to keep things cloud provider-agnostic, this proved to be somewhat impractical due to the graphs required to better illustrate the architectures discussed in this blog series. That being said, one could replace AWS Lambda with Azure Functions or GCP Cloud Functions and the design patterns discussed here would be just as valid; both Azure as well as GCP have a plethora of their managed services available as triggers to their respective on-demand compute services that run custom code in response to events from those services, or in serverless lingo: invocations.
The good parts
Increasing observability, reducing complexity
Microservices enable developers and architects to decompose complex workflows. For example, an ecommerce monolith may be broken down into order acceptance and payment processes with separate inventory, fulfillment and accounting services. What may be complex to manage and orchestrate in a monolith becomes a series of decoupled services that communicate asynchronously with event messages.
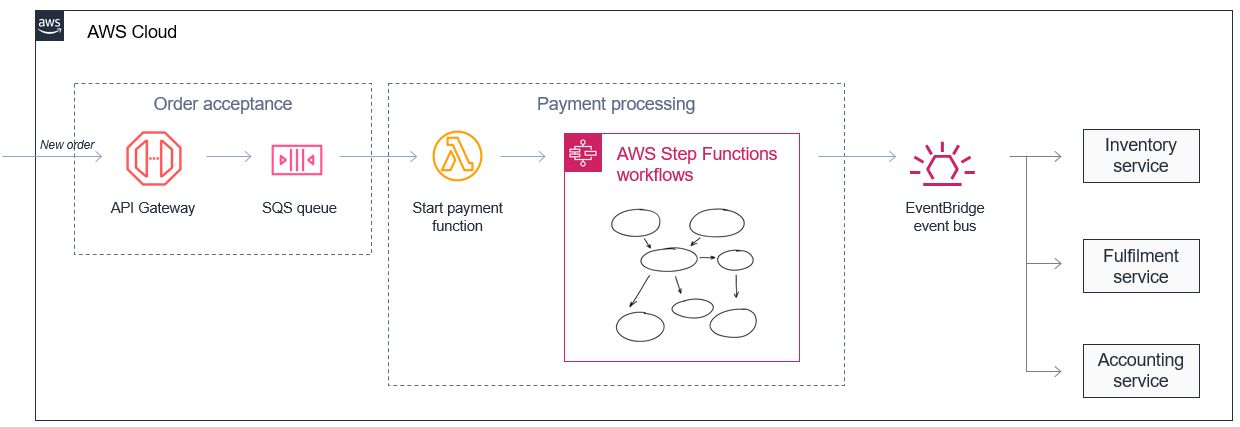
This approach also makes it possible to assemble services that process data at different rates. In this case, an order acceptance microservice can store high volumes of incoming orders by buffering the messages in an AWS SQS queue (or Azure Bus Service etc.).
A payment processing service, which is typically slower due to the complexity of handling payments, can take a steady stream of messages from the SQS queue. It can orchestrate complex retry and error handling logic using a managed state machine service such as AWS Step Functions (or Azure Durable Functions etc.), and coordinate active payment workflows for hundreds of thousands of orders.
Structured JSON events versus polling & custom webhooks
Many traditional architectures frequently use polling and webhook mechanisms to communicate state between different components. Polling can be highly inefficient for fetching updates since there is lag introduced between new data becoming available and synchronization with downstream services. Webhooks are not always supported by other microservices that you want to integrate with. They may also require custom authorization and authentication configurations. In both cases, these integration methods are challenging to scale on-demand without additional work by development teams.
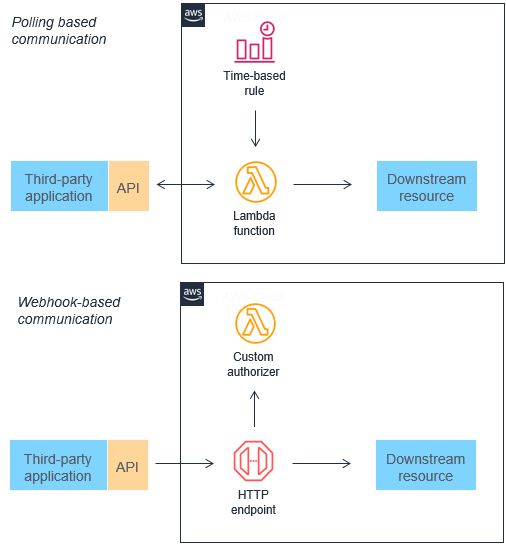
Both of these mechanisms can be replaced by events, which can be filtered, routed, and pushed downstream to consuming microservices. This approach can result in less bandwidth consumption, CPU utilization, and potentially lower cost. These architectures can reduce complexity, since each functional unit is smaller and there is often less code (I'll probably write about this in a separate post with some hard numbers because my startup has actually underwent that transition already).
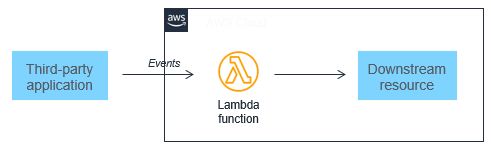
Event-driven architectures can also make it easier to design near-real-time systems, helping organizations move away from batch-based processing. Events are generated at the time when state in the application changes, so the custom code of a microservice should be designed to handle the processing of a single event. Since scaling is handled by the Lambda service, this architecture can handle significant increases in traffic without changing custom code. As events scale up, so does the compute layer that processes events.
Improving scalability and extensibility
Microservices generate events that are typically published to messaging services like SNS and SQS. These behave like an elastic buffer between microservices and help handle scaling when traffic increases. Services like AWS EventBridge, which is a managed service that delivers a stream of real-time data from various events to targets like Lambda, can then filter and route messages depending upon the content of the event, as defined in rules. As a result, event-based applications can be more scalable and offer greater redundancy than monolithic applications.
This system is also highly extensible, allowing other teams to extend features and add functionality without impacting the order processing and payment processing microservices. By publishing events using EventBridge, this application integrates with existing systems, such as the inventory microservice, but also enables any future application to integrate as an event consumer. Producers of events have no knowledge of event consumers, which can help simplify the microservice logic.
Trade-offs
Consistent low-latency is impossible
Unlike monolithic applications, which may process everything within the same memory space on a single device, event-driven applications communicate across networks. This design introduces variable latency. While it’s possible to engineer applications to minimize latency, monolithic applications can almost always be optimized for lower latency at the expense of scalability and availability.
Serverless services in AWS (as well as other cloud providers) are highly available, meaning that they operate in more than one Availability Zone in a Region. In the event of a service disruption, services automatically fail over to alternative Availability Zones and retry transactions. As a result, instead of a transaction failing, it may be completed successfully but with higher latency.
Workloads that require consistent low-latency performance are not good candidates for event-driven architecture.
Eventual consistency
An event represents a change in state. With many events flowing through different services in an architecture at any given point of time, such workloads are often eventually consistent. This makes it more complex to process transactions, handle duplicates, or determine the exact overall state of a system.
Some workloads are not well suited for event-driven architecture, due to the need for ACID properties. However, many workloads contain a combination of requirements that are eventually consistent (for example, total orders in the current hour) or strongly consistent (for example, current inventory). For those features needing strong data consistency, there are architecture patterns to support this.
Event-based architectures are designed around individual events instead of large batches of data. Generally, workflows are designed to manage the steps of an individual event or execution flow instead of operating on multiple events simultaneously. Real-time event processing is preferred to batch processing in event-driven systems, replacing a batch with many small incremental updates. While this can make workloads more available and scalable, it also makes it more challenging for events to have awareness of other events.
I'll show ways of working effectively within these constraints👆 in a following post in this blog series, specifically when designing a serverless reporting engine.
Returning values to callers
This probably is the single most frequent yet also not exactly straightforward to implement in a serverless platform, feature for any web or mobile application. In most cases, event-based applications are asynchronous. This means that caller services do not wait for requests from other services before continuing with other work. This is a fundamental characteristic of event-driven architectures that enables scalability and flexibility. This means that passing return values or the result of a workflow is often more complex than in synchronous execution flows.
Most Lambda invocations in productions systems are asynchronous, responding to events from services like S3 or SQS. In these cases, the success or failure of processing an event is often more important than returning a value. Features such as dead letter queues (DLQs) in Lambda are provided to ensure you can identify and retry failed events, without needing to notify the caller.
For interactive workloads, such as web and mobile applications, the end user usually expects to receive a return value or a current status of a transaction. For these workloads, I'll show ways of achieving this on a subsequent blog post. However, these implementations are undeniably more complex than using a traditional asynchronous return value.
Debugging across services and functions
Debugging event-driven systems is also different to solving problems within a monolithic application, because hey in which process are you going to attach that debugger to?

With different systems and services passing events, it is often cumbersome to record and reproduce the exact state of multiple services when an error occurs. Since each service and function invocation has separate log files, it can be more complicated to determine what happened to a specific event that caused an error.
No worries though, I'll cover how to make this process easier too :-)
Coming Up Next
In the next post, I'll cover the design principles in building applications in a serverless platform using event-driven architectures.
In the follow-up posts, I'll cover each of the following SaaS use cases separately:
- The serverless equivalent of uploading a file from a front-end to an application's backend for further processing
- Design scheduled tasks such as CRON jobs, a la serverless
- Design a serverless video uploading and transcoding platform
- Design a reporting engine, effectively handling eventual consistency in the process
References