Event-Driven Architectures: Patterns

In the first part of the Event-Driven Architecture series, I touched upon the pros and cons of using event-driven architectures when designing serverless applications. In this second part, I will go over some do's and don'ts when implementing event-driven serverless applications, in a nutshell. The goal here is for colleagues to treat those as design guidelines more than mere suggestions; one should only violate any one of those fully aware of the design trade-offs involved.
Statelessness
When building serverless functions, one should assume that the environment exists only for a single invocation (the jury is still out on this one but this deserves a separate post; for the context of this article the statement above is true). The function should initialize any required state when it is first started – for example, fetching a shopping cart from a database table. It should commit any permanent data changes before exiting to a durable store such as a managed queue service, a blob storage service or a database. It should not rely on any existing data structures or temporary files, or any internal state that would be managed by multiple invocations (such as counters or other calculated, aggregate values).
AWS Lambda, for instance, provides an initializer before the handler where you can initialize database connections, libraries, and other resources. Since execution environments are reused where possible to improve performance, you can amortize the time taken to initialize these resources over multiple invocations. However, you should not store any variables or data used in the function within this global scope.
A practical example of 👆 from the .NET world would be initializing an Entity Framework Core database context; that kind of operation is computationally expensive so we'd want to re-use this as much as possible.
Managed services > custom code
It just doesn't make a lot of sense, from a Return Of Investment (ROI) or commercial value standpoint, to build or implement custom code for well-established patters of distributed systems architectures; the following is a table of such patterns and corresponding AWS services one might use instead:
| Pattern | AWS service |
| Queue | Amazon SQS |
| Event bus | Amazon EventBridge |
| Publish/subscribe (fan-out) | Amazon SNS |
| Orchestration | AWS Step Functions |
| API | Amazon API Gateway |
| Event streams | Amazon Kinesis |
These services are designed to integrate with Lambda and you can use infrastructure as code (IaC) to create and discard resources in the services (using cloud native services like CloudFormation or otherwise with third party tools like Terraform or Ansible). Becoming proficient with using these services via code in your Lambda functions is an important step to producing well-designed serverless applications.
On-demand data instead of batches
Many traditional systems are designed to run periodically and process batches of transactions that have built up over time. For example, a banking application may run every hour to process ATM transactions into central ledgers. In Lambda-based applications, the custom processing should be triggered by every event, allowing the service to scale up concurrency as needed, to provide near-real time processing of transactions.
While you can run cron tasks in serverless applications by using scheduled expressions for rules in Amazon EventBridge, these should be used sparingly or as a last-resort. In any scheduled task that processes a batch, there is the potential for the volume of transactions to grow beyond what can be processed within the 15-minute Lambda timeout. If the limitations of external systems force you to use a scheduler, you should generally schedule for the shortest reasonable recurring time period.
For example, it’s not best practice to use a batch process that triggers a Lambda function to fetch a list of new S3 objects. This is because the service may receive more new objects in between batches than can be processed within a 15-minute Lambda function.
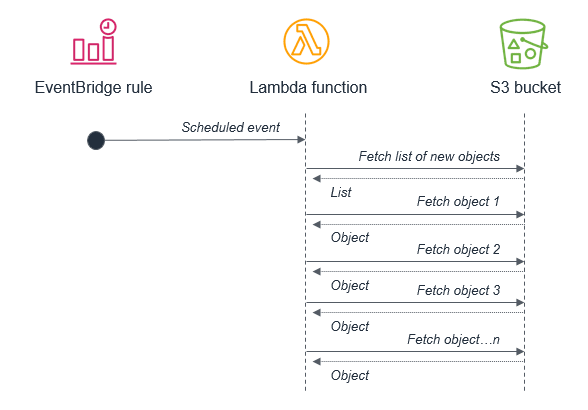
Instead, the Lambda function should be invoked by the S3 service each time a new object is put into the S3 bucket. This approach is significantly more scalable and also invokes processing in near-real time.
Orchestration
Enterprise workflows that involve branching logic, different types of failure models and retry logic typically use an orchestrator to keep track of the state of the overall execution. Avoid using Lambda/Azure functions for this purpose at all costs, since it results in tightly coupled groups of functions and services and complex code handling routing and exceptions.
With AWS Step Functions, one can use state machines to manage orchestration. This extracts the error handling, routing, and branching logic from your code, replacing it with state machines declared using JSON. Apart from making workflows more robust and observable, it allows you to add versioning to workflows and make the state machine a codified resource that you can add to a code repository. Azure Orchestrator Functions uses a significantly different mental model, utilizing code over configuration, to achieve the same result.
It’s common for simpler workflows in serverless functions to become more complex over time, and for developers to use a Lambda function to orchestrate the flow. When operating a production serverless application, it’s important to identify when this is happening, so you can migrate this logic to a state machine. Doing this sooner rather than later is critical; I realize there is a steep learning curve in refactoring existing serverless apps to a state machine defined in JSON but I cannot overemphasize the importance of going ahead with this transition. If you do not; these tightly-coupled functions can truly get out of hand quickly and debugging will end up being a nightmare without very specific tools (I'll talk about these more in a future post of this series). It's a recipe for destruction.
Develop for resilience & design around failures
Public cloud serverless services, including Lambda, are fault-tolerant and designed to handle failures. In the case of Lambda, if a service invokes a Lambda function and there is a service disruption, Lambda invokes your function in a different Availability Zone. If your function throws an error, the Lambda service retries your function; the default value for that is 3 times.
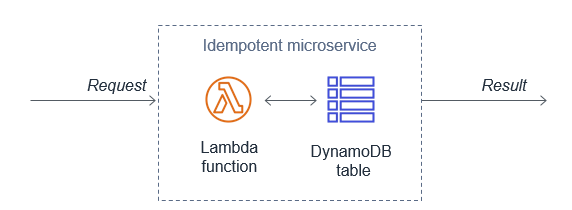
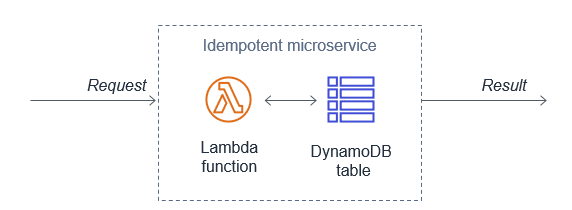
Since the same event may be received more than once, functions should be designed to be idempotent. This means that receiving the same event multiple times does not change the result beyond the first time the event was received.
For example, if a credit card transaction is attempted twice due to a retry, the Lambda function should process the payment on the first receipt. On the second retry, either the Lambda function should discard the event or the downstream service it uses should be idempotent.
A Lambda function implements idempotency typically by using a DynamoDB table to track recently processed identifiers to determine if the transaction has been handled previously. The DynamoDB table usually implements a Time To Live (TTL) value to expire items to limit the storage space used.
For failures, one has a couple of options when it comes to preserving the error context and exception stacks but let's just say that you should treat this part no differently than you would on a "traditional" application: BYO exception handling. Plugging logging providers in to improve diagnosis is also as straightforward as in a web app, provided you have created a framework for handling these cross-cutting concerns (I will address this separately in a future post).
Next steps
These patterns are lessons learned in the trenches over the past few years of building distributed systems in serverless platforms. I am sure there are more out there, so feel free to drop a comment below with any additional ones or discuss the ones mentioned here in greater length.
The next post in this series will go over common anti-patterns in event-driven architectures and how to avoid building these into your microservices.
References